- seaborn.boxplot¶
- Как понимать Boxplot?
- Открытый курс машинного обучения. Тема 2: Визуализация данных c Python
- План этой статьи
- Демонстрация основных методов Seaborn и Plotly
- Seaborn
- Plotly
- Пример визуального анализа данных
- Подглядывание в n-мерное пространство с t-SNE
- Домашнее задание № 2
- Обзор полезных ресурсов
seaborn.boxplot¶
Draw a box plot to show distributions with respect to categories.
A box plot (or box-and-whisker plot) shows the distribution of quantitative data in a way that facilitates comparisons between variables or across levels of a categorical variable. The box shows the quartiles of the dataset while the whiskers extend to show the rest of the distribution, except for points that are determined to be “outliers” using a method that is a function of the inter-quartile range.
Input data can be passed in a variety of formats, including:
Vectors of data represented as lists, numpy arrays, or pandas Series objects passed directly to the x , y , and/or hue parameters.
A “long-form” DataFrame, in which case the x , y , and hue variables will determine how the data are plotted.
A “wide-form” DataFrame, such that each numeric column will be plotted.
An array or list of vectors.
In most cases, it is possible to use numpy or Python objects, but pandas objects are preferable because the associated names will be used to annotate the axes. Additionally, you can use Categorical types for the grouping variables to control the order of plot elements.
This function always treats one of the variables as categorical and draws data at ordinal positions (0, 1, … n) on the relevant axis, even when the data has a numeric or date type.
See the tutorial for more information.
Parameters x, y, hue names of variables in data or vector data, optional
Inputs for plotting long-form data. See examples for interpretation.
data DataFrame, array, or list of arrays, optional
Dataset for plotting. If x and y are absent, this is interpreted as wide-form. Otherwise it is expected to be long-form.
order, hue_order lists of strings, optional
Order to plot the categorical levels in, otherwise the levels are inferred from the data objects.
orient “v” | “h”, optional
Orientation of the plot (vertical or horizontal). This is usually inferred based on the type of the input variables, but it can be used to resolve ambiguitiy when both x and y are numeric or when plotting wide-form data.
color matplotlib color, optional
Color for all of the elements, or seed for a gradient palette.
palette palette name, list, or dict
Colors to use for the different levels of the hue variable. Should be something that can be interpreted by color_palette() , or a dictionary mapping hue levels to matplotlib colors.
saturation float, optional
Proportion of the original saturation to draw colors at. Large patches often look better with slightly desaturated colors, but set this to 1 if you want the plot colors to perfectly match the input color spec.
width float, optional
Width of a full element when not using hue nesting, or width of all the elements for one level of the major grouping variable.
dodge bool, optional
When hue nesting is used, whether elements should be shifted along the categorical axis.
fliersize float, optional
Size of the markers used to indicate outlier observations.
linewidth float, optional
Width of the gray lines that frame the plot elements.
whis float, optional
Proportion of the IQR past the low and high quartiles to extend the plot whiskers. Points outside this range will be identified as outliers.
ax matplotlib Axes, optional
Axes object to draw the plot onto, otherwise uses the current Axes.
kwargs key, value mappings
Other keyword arguments are passed through to matplotlib.axes.Axes.boxplot() .
Returns ax matplotlib Axes
Returns the Axes object with the plot drawn onto it.
A combination of boxplot and kernel density estimation.
A scatterplot where one variable is categorical. Can be used in conjunction with other plots to show each observation.
A categorical scatterplot where the points do not overlap. Can be used with other plots to show each observation.
Combine a categorical plot with a FacetGrid .
Draw a single horizontal boxplot:

Draw a vertical boxplot grouped by a categorical variable:

Draw a boxplot with nested grouping by two categorical variables:

Draw a boxplot with nested grouping when some bins are empty:

Control box order by passing an explicit order:

Draw a boxplot for each numeric variable in a DataFrame:

Use hue without changing box position or width:

Use swarmplot() to show the datapoints on top of the boxes:

Use catplot() to combine a boxplot() and a FacetGrid . This allows grouping within additional categorical variables. Using catplot() is safer than using FacetGrid directly, as it ensures synchronization of variable order across facets:
Источник статьи: http://seaborn.pydata.org/generated/seaborn.boxplot.html
Как понимать Boxplot?

Вот, что показывает боксплот:
Медиана – это значение элемента в центре ранжированного ряда.
Например, если всех осьминогов выставить в порядке возрастания их оценок, то медианой будет та оценка, которую поставил осьминог в середине. А это значит, что половина осьминогов справа оценили вероятность покупки ниже, а другая половина (слева) выше, чем медианный.
Верхний квартиль – это такая оценка, выше которой только 25% оценок.
Нижний квартиль – это такое значение, ниже которого только 25% оценок.
Межквартильный размах (МКР) – это разница между 75% и 25% квартилем. Внутри этого диапазона лежит 50% наблюдений. Если диапазон узкий (как в случае с осьминогами), значит члены подгруппы единогласны в своих оценках. Если широкий – значит однородного мнения нет (как у цыплят).
Выбросы – это нетипичные наблюдения. Что именно считать нетипичным? Те оценки, которые выходят за пределы:
- значения 25% перцентили минус 1.5 х МКР
- значения 75% перцентили плюс 1.5 х МКР
Уровень значимости не имеет отношения к ящику, но часто результаты стат. тестов и боксплоты удобно показать вместе. Коротко: если p-value меньше 0.05, значит различия между подгруппами НЕ случайны (т.е. различия между подгруппам статистически значимы).
А теперь по-нормальному: p-value – это вероятность ошибки, при отказе от нулевой гипотезы. Или вероятность получить такие или еще более значимые отклонение выборочного среднего, если верна нулевая гипотеза (т.е. отличий между группами в генеральной совокупности нет). Подробнее про всю эту жуть здесь.
Источник статьи: http://tidydata.ru/boxplot
Открытый курс машинного обучения. Тема 2: Визуализация данных c Python

Второе занятие посвящено визуализации данных в Python. Сначала мы посмотрим на основные методы библиотек Seaborn и Plotly, затем поанализируем знакомый нам по первой статье набор данных по оттоку клиентов телеком-оператора и подглядим в n-мерное пространство с помощью алгоритма t-SNE. Есть и видеозапись лекции по мотивам этой статьи в рамках второго запуска открытого курса (сентябрь-ноябрь 2017).
UPD: теперь курс — на английском языке под брендом mlcourse.ai со статьями на Medium, а материалами — на Kaggle (Dataset) и на GitHub.
Сейчас статья уже будет существенно длиннее. Готовы? Поехали!
План этой статьи
Демонстрация основных методов Seaborn и Plotly
В начале как всегда настроим окружение: импортируем все необходимые библиотеки и немного настроим дефолтное отображение картинок.
После этого загрузим в DataFrame данные, с которыми будем работать. Для примеров я выбрала данные о продажах и оценках видео-игр из Kaggle Datasets.
Некоторые признаки, которые pandas считал как object , явно приведем к типам float или int .
Данные есть не для всех игр, поэтому давайте оставим только те записи, в которых нет пропусков, с помощью метода dropna .
Всего в таблице 6825 объектов и 16 признаков для них. Посмотрим на несколько первых записей c помощью метода head , чтобы убедиться, что все распарсилось правильно. Для удобства я оставила только те признаки, которые мы будем в дальнейшем использовать.

Прежде чем мы перейдем к рассмотрению методов библиотек seaborn и plotly , обсудим самый простой и зачастую удобный способ визуализировать данные из pandas DataFrame — это воспользоваться функцией plot .
Для примера построим график продаж видео игр в различных странах в зависимости от года. Для начала отфильтруем только нужные нам столбцы, затем посчитаем суммарные продажи по годам и у получившегося DataFrame вызовем функцию plot без параметров.
Реализация функции plot в pandas основана на библиотеке matplotlib .
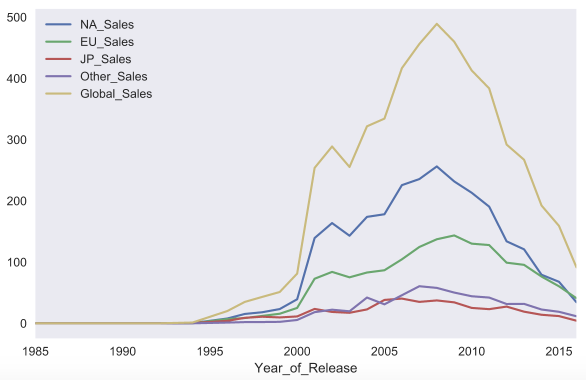
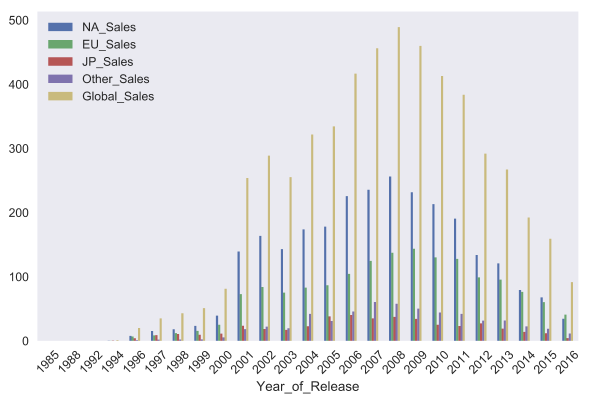
C помощью параметра kind можно изменить тип графика, например, на bar chart . Matplotlib позволяет очень гибко настраивать графики. На графике можно изменить почти все, что угодно, но потребуется порыться в документации и найти нужные параметры. Например, параметр rot отвечает за угол наклона подписей к оси x .
Seaborn
Теперь давайте перейдем к библиотеке seaborn . Seaborn — это по сути более высокоуровневое API на базе библиотеки matplotlib . Seaborn содержит более адекватные дефолтные настройки оформления графиков. Также в библиотеке есть достаточно сложные типы визуализации, которые в matplotlib потребовали бы большого количество кода.
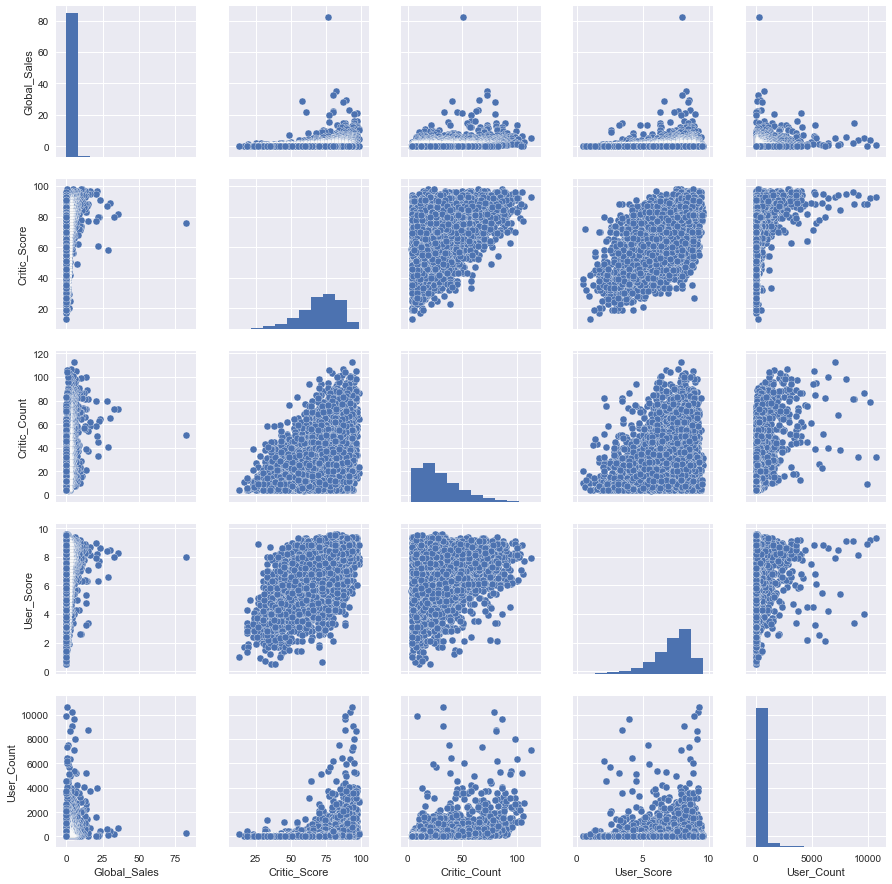
Познакомимся с первым таким «сложным» типом графиков pair plot ( scatter plot matrix ). Эта визуализация поможет нам посмотреть на одной картинке, как связаны между собой различные признаки.
Как можно видеть, на диагонали матрицы графиков расположены гистограммы распределений признака. Остальные же графики — это обычные scatter plots для соответствующих пар признаков.
Для сохранения графиков в файлы стоит использовать метод savefig .
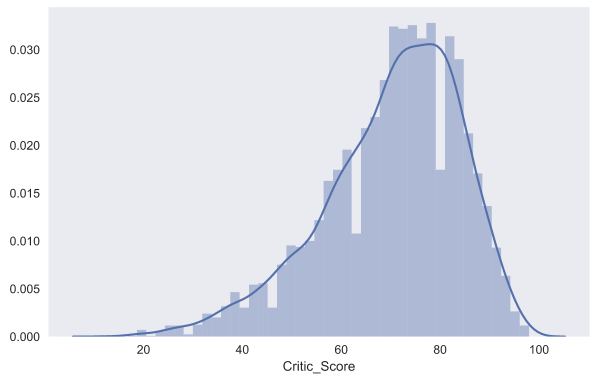
С помощью seaborn можно построить и распределение dist plot . Для примера посмотрим на распределение оценок критиков Critic_Score . По умолчанию на графике отображается гистограмма и kernel density estimation.
Для того, чтобы подробнее посмотреть на взаимосвязь двух численных признаков, есть еще и joint plot — это гибрид scatter plot и histogram . Посмотрим на то, как связаны между собой оценка критиков Critic_Score и оценка пользователя User_Score .
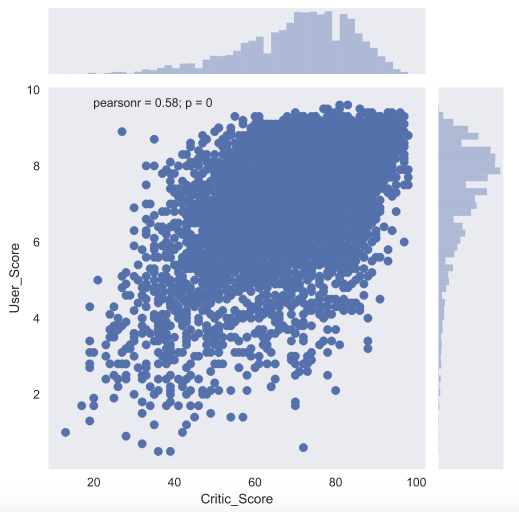
Еще один полезный тип графиков — это box plot . Давайте сравним оценки игр от критиков для топ-5 крупнейших игровых платформ.
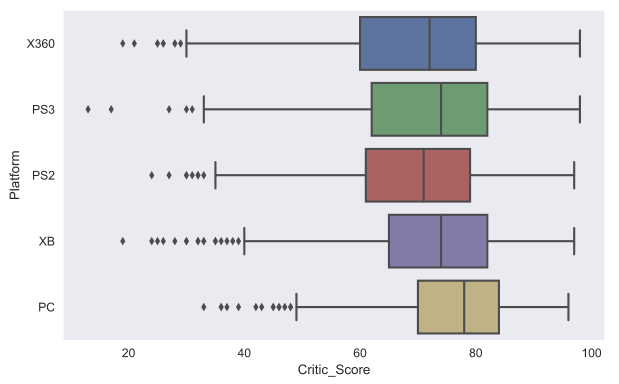
Думаю, стоит обсудить немного подробнее, как же понимать box plot . Box plot состоит из коробки (поэтому он и называется box plot ), усиков и точек. Коробка показывает интерквартильный размах распределения, то есть соответственно 25% ( Q1 ) и 75% ( Q3 ) перцентили. Черта внутри коробки обозначает медиану распределения.
С коробкой разобрались, перейдем к усам. Усы отображают весь разброс точек кроме выбросов, то есть минимальные и максимальные значения, которые попадают в промежуток (Q1 — 1.5*IQR, Q3 + 1.5*IQR) , где IQR = Q3 — Q1 — интерквартильный размах. Точками на графике обозначаются выбросы ( outliers ) — те значения, которые не вписываются в промежуток значений, заданный усами графика.
Для понимания лучше один раз увидеть, поэтому вот еще и картинка с Wikipedia: 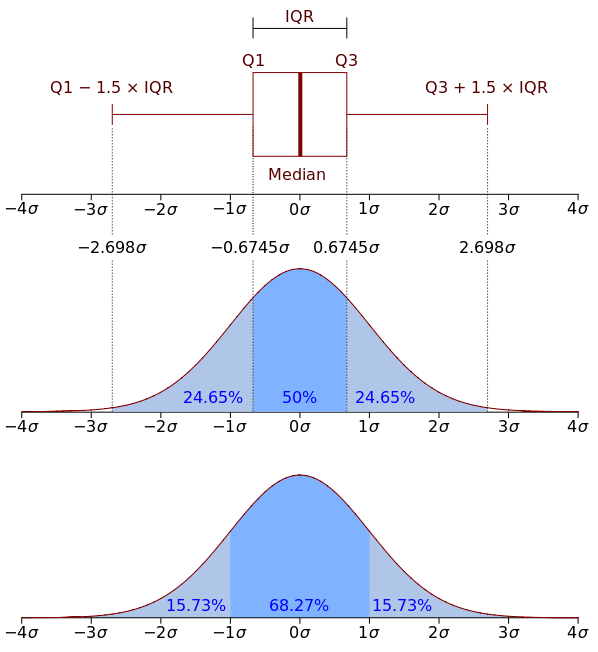
И еще один тип графиков (последний из тех, которые мы рассмотрим в этой статье) — это heat map . Heat map позволяет посмотреть на распределение какого-то численного признака по двум категориальным. Визуализируем суммарные продажи игр по жанрам и игровым платформам.
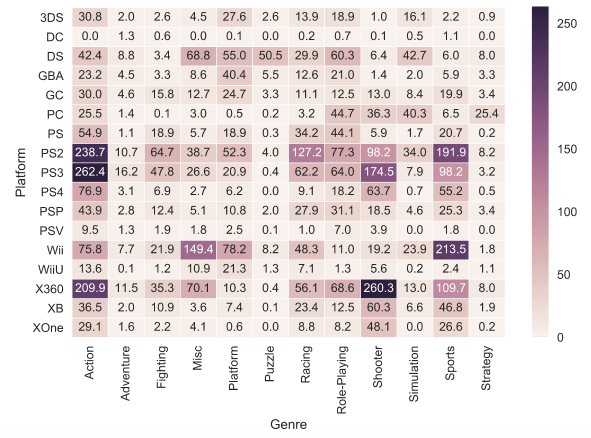
Plotly
Мы рассмотрели визуализации на базе библиотеки matplotlib . Однако это не единственная опция для построения графиков на языке python . Познакомимся также с библиотекой plotly . Plotly — это open-source библиотека, которая позволяет строить интерактивные графики в jupyter.notebook’e без необходимости зарываться в javascript код.
Прелесть интерактивных графиков заключается в том, что можно посмотреть точное численное значение при наведении мыши, скрыть неинтересные ряды в визуализации, приблизить определенный участок графика и т.д.
Перед началом работы импортируем все необходимые модули и инициализируем plotly с помощью команды init_notebook_mode .
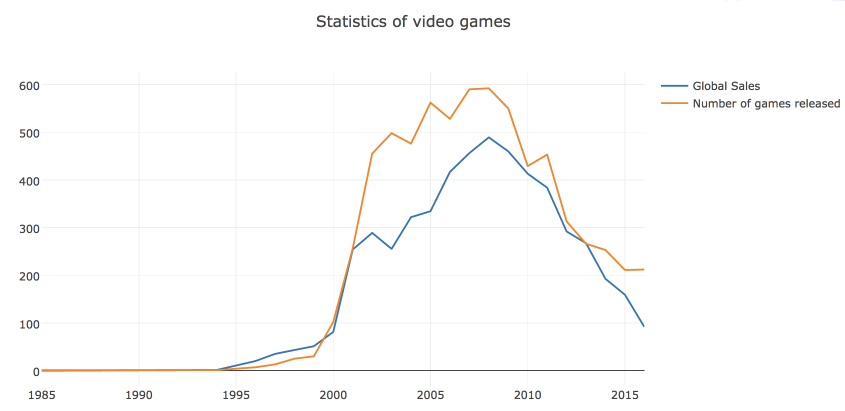
Для начала построим line plot с динамикой числа вышедших игр и их продаж по годам.
В plotly строится визуализация объекта Figure , который состоит из данных (массив линий, которые в библиотеке называются traces ) и оформления/стиля, за который отвечает объект layout . В простых случаях можно вызывать функцию iplot и просто от массива traces .
Параметр show_link отвечает за ссылки на online-платформу plot.ly на графиках. Поскольку обычно это функциональность не нужна, то я предпочитаю скрывать ее для предотвращения случайных нажатий.
Можно сразу сохранить график в виде html-файла.
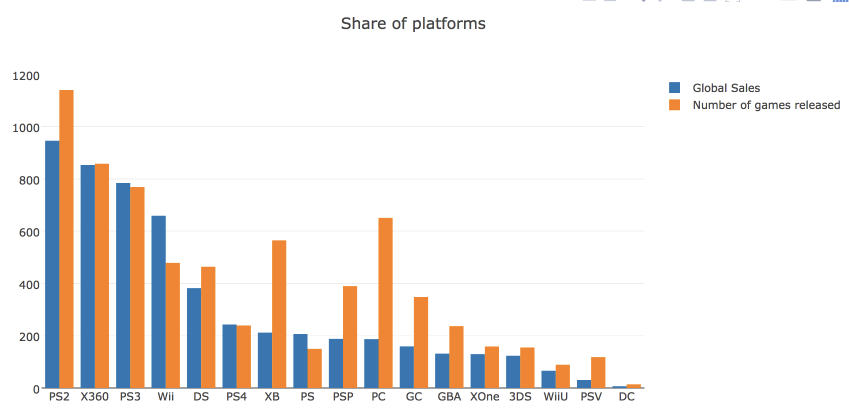
Посмотрим также на рыночную долю игровых платформ, рассчитанную по количеству выпущенных игр и по суммарной выручке. Для этого построим bar chart .
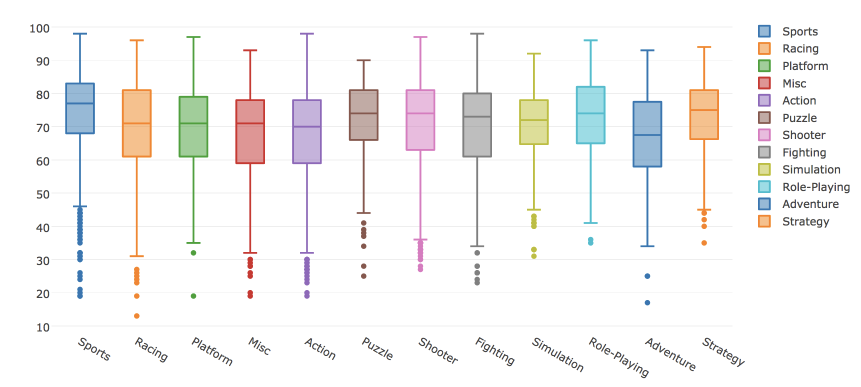
В plotly можно построить и box plot . Рассмотрим распределения оценок критиков в зависимости от жанра игры.
С помощью plotly можно построить и другие типы визуализаций. Графики получаются достаточно симпатичными с дефолтными настройками. Однако библиотека позволяет и гибко настраивать различные параметры визуализации: цвета, шрифты, подписи, аннотации и многое другое.
Пример визуального анализа данных
Считываем в DataFrame знакомые нам по первой статье данные по оттоку клиентов телеком-оператора.
Проверим, все ли нормально считалось – посмотрим на первые 5 строк (метод head ).

Число строк (клиентов) и столбцов (признаков):
Посмотрим на признаки и убедимся, что пропусков ни в одном из них нет – везде по 3333 записи.
| Название | Описание | Тип |
|---|---|---|
| State | Буквенный код штата | категориальный |
| Account length | Как долго клиент обслуживается компанией | количественный |
| Area code | Префикс номера телефона | количественный |
| International plan | Международный роуминг (подключен/не подключен) | бинарный |
| Voice mail plan | Голосовая почта (подключена/не подключена) | бинарный |
| Number vmail messages | Количество голосовых сообщений | количественный |
| Total day minutes | Общая длительность разговоров днем | количественный |
| Total day calls | Общее количество звонков днем | количественный |
| Total day charge | Общая сумма оплаты за услуги днем | количественный |
| Total eve minutes | Общая длительность разговоров вечером | количественный |
| Total eve calls | Общее количество звонков вечером | количественный |
| Total eve charge | Общая сумма оплаты за услуги вечером | количественный |
| Total night minutes | Общая длительность разговоров ночью | количественный |
| Total night calls | Общее количество звонков ночью | количественный |
| Total night charge | Общая сумма оплаты за услуги ночью | количественный |
| Total intl minutes | Общая длительность международных разговоров | количественный |
| Total intl calls | Общее количество международных разговоров | количественный |
| Total intl charge | Общая сумма оплаты за международные разговоры | количественный |
| Customer service calls | Число обращений в сервисный центр | количественный |
Целевая переменная: Churn – Признак оттока, бинарный (1 – потеря клиента, то есть отток). Потом мы будем строить модели, прогнозирующие этот признак по остальным, поэтому мы и назвали его целевым.
Посмотрим на распределение целевого класса – оттока клиентов.
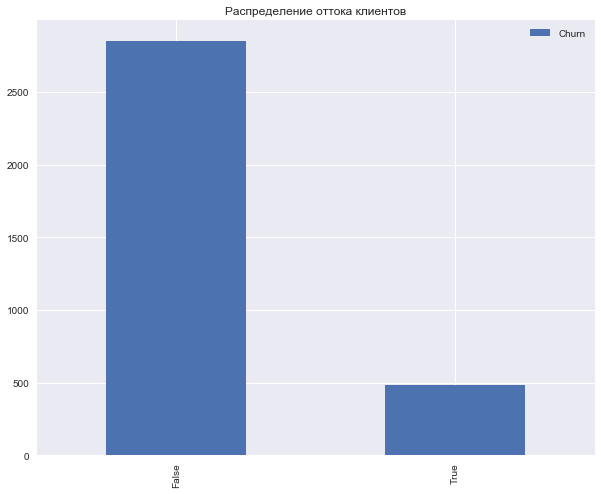
Выделим следующие группы признаков (среди всех кроме Churn ):
- бинарные: International plan, Voice mail plan
- категориальные: State
- порядковые: Customer service calls
- количественные: все остальные
Посмотрим на корреляции количественных признаков. По раскрашенной матрице корреляций видно, что такие признаки как Total day charge считаются по проговоренным минутам (Total day minutes). То есть 4 признака можно выкинуть, они не несут полезной информации.
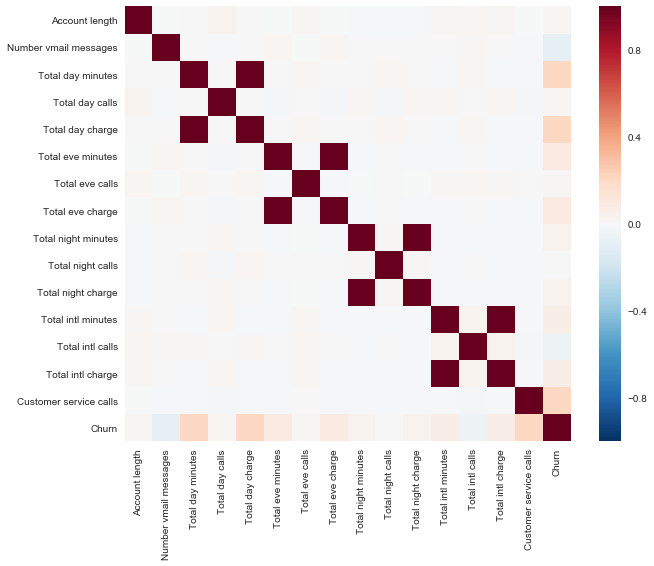
Теперь посмотрим на распределения всех интересующих нас количественных признаков. На бинарные/категориальные/порядковые признакие будем смотреть отдельно.

Видим, что большинство признаков распределены нормально. Исключения – число звонков в сервисный центр (Customer service calls) (тут больше подходит пуассоновское распределение) и число голосовых сообщений (Number vmail messages, пик в нуле, т.е. это те, у кого голосовая почта не подключена). Также смещено распределение числа международных звонков (Total intl calls).
Еще полезно строить вот такие картинки, где на главной диагонали рисуются распределения признаков, а вне главной диагонали – диаграммы рассеяния для пар признаков. Бывает, что это приводит к каким-то выводам, но в данном случае все примерно понятно, без сюрпризов.

Дальше посмотрим, как признаки связаны с целевым – с оттоком.
Построим boxplot-ы, описывающее статистики распределения количественных признаков в двух группах: среди лояльных и ушедших клиентов.

На глаз наибольшее отличие мы видим для признаков Total day minutes, Customer service calls и Number vmail messages. Впоследствии мы научимся определять важность признаков в задаче классификации с помощью случайного леса (или градиентного бустинга), и окажется, что первые два – действительно очень важные признаки для прогнозирования оттока.
Посмотрим отдельно на картинки с распределением кол-ва проговоренных днем минут среди лояльных/ушедших. Слева — знакомые нам боксплоты, справа – сглаженные гистограммы распределения числового признака в двух группах (скорее просто красивая картинка, все и так понятно по боксплоту).
Интересное наблюдение: в среднем ушедшие клиенты больше пользуются связью. Возможно, они недовольны тарифами, и одной из мер борьбы с оттоком будет понижение тарифных ставок (стоимости мобильной связи). Но это уже компании надо будет проводить дополнительный экономический анализ, действительно ли такие меры будут оправданы.

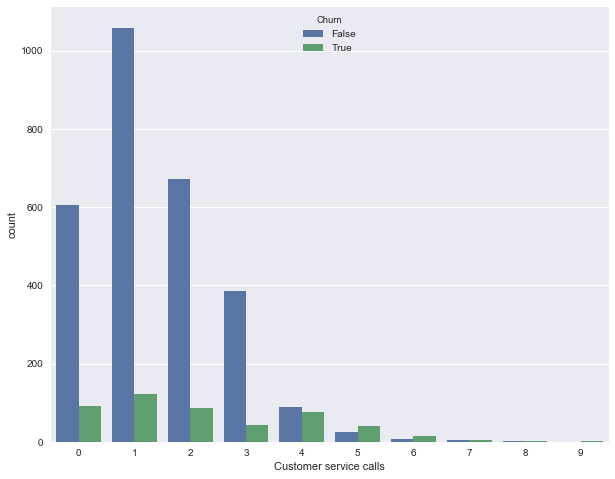
Теперь изобразим распределение числа обращений в сервисный центр (такую картинку мы строили в первой статье). Тут уникальных значений признака не много (признак можно считать как количественным целочисленным, так и порядковым), и наглядней изобразить распределение с помощью countplot . Наблюдение: доля оттока сильно возрастает начиная с 4 звонков в сервисный центр.
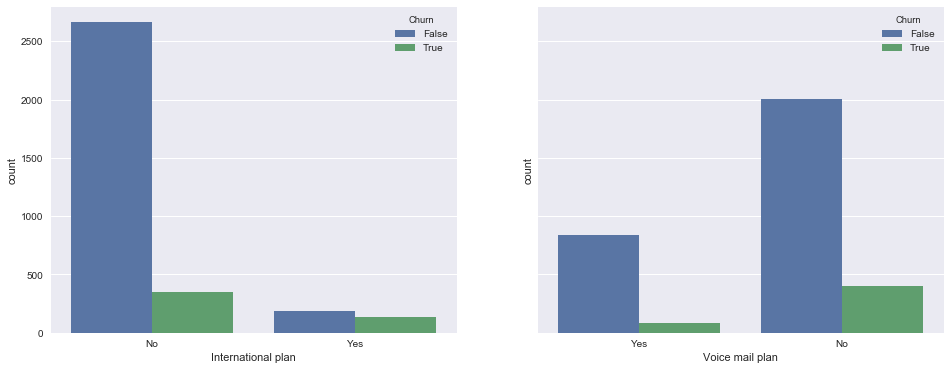
Теперь посмотрим на связь бинарных признаков International plan и Voice mail plan с оттоком. Наблюдение: когда роуминг подключен, доля оттока намного выше, т.е. наличие международного роуминга – сильный признак. Про голосовую почту такого нельзя сказать.
Наконец, посмотрим, как с оттоком связан категориальный признак State. С ним уже не так приятно работать, поскольку число уникальных штатов довольно велико – 51. Можно в начале построить сводную табличку или посчитать процент оттока для каждого штата. Но данных по каждом штату по отдельности маловато (ушедших клиентов всего от 3 до 17 в каждом штате), поэтому, возможно, признак State впоследствии не стоит добавлять в модели классификации из-за риска переобучения (но мы это будем проверять на кросс-валидации, stay tuned!).
Доли оттока для каждого штата:


Видно, что в Нью-Джерси и Калифорнии доля оттока выше 25%, а на Гавайях и в Аляске меньше 5%. Но эти выводы построены на слишком скромной статистике и возможно, это просто особенности имеющихся данных (тут можно и гипотезы попроверять про корреляции Мэтьюса и Крамера, но это уже за рамками данной статьи).
Подглядывание в n-мерное пространство с t-SNE
Построим t-SNE представление все тех же данных по оттоку. Название метода сложное – t-distributed Stohastic Neighbor Embedding, математика тоже крутая (и вникать в нее не будем, но для желающих – вот оригинальная статья Д. Хинтона и его аспиранта в JMLR), но основная идея проста, как дверь: найдем такое отображение из многомерного признакового пространства на плоскость (или в 3D, но почти всегда выбирают 2D), чтоб точки, которые были далеко друг от друга, на плоскости тоже оказались удаленными, а близкие точки – также отобразились на близкие. То есть neighbor embedding – это своего рода поиск нового представления данных, при котором сохраняется соседство.
Немного деталей: выкинем штаты и признак оттока, бинарные Yes/No-признаки переведем в числа ( pd.factorize ). Также нужно масштабировать выборку – из каждого признака вычесть его среднее и поделить на стандартное отклонение, это делает StandardScaler .
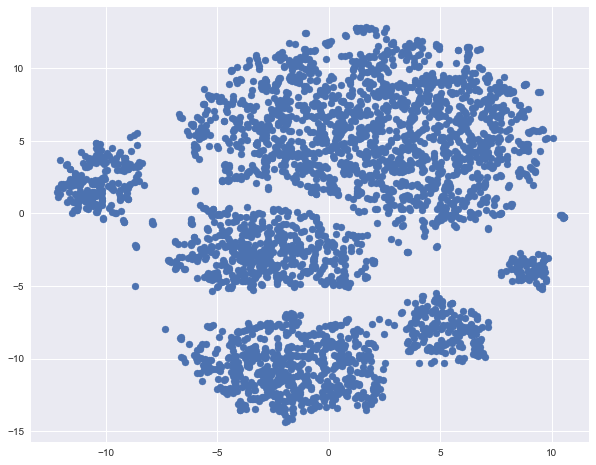
Раскрасим полученное t-SNE представление данных по оттоку (синие – лояльные, оранжевые – ушедшие клиенты).

Видим, что ушедшие клиенты преимущественно «кучкуются» в некоторых областях признакового пространства.
Чтоб лучше понять картинку, можно также раскрасить ее по остальным бинарным признакам – по роумингу и голосовой почте. Синие участки соответствуют объектам, обладающим этим бинарным признаком.
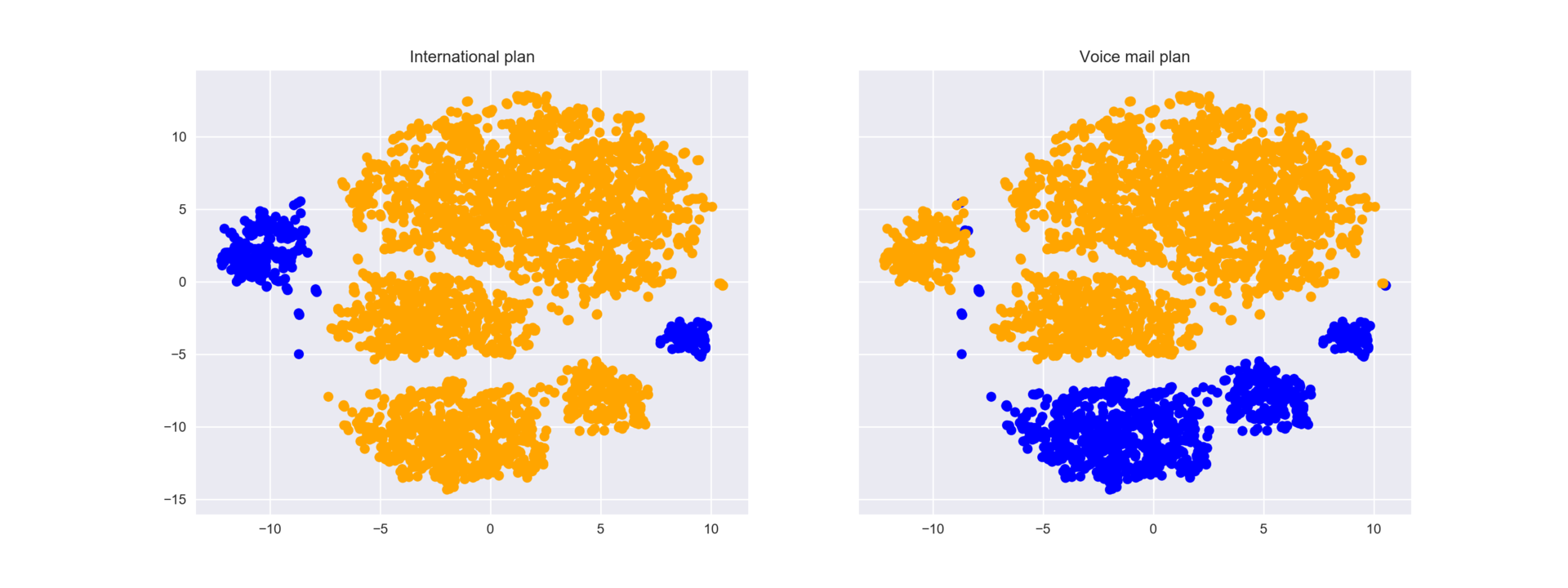
Теперь понятно, что, например, много ушедших клиентов кучкуется в левом кластере людей с поключенным роумингом, но без голосовой почты.
Напоследок отметим минусы t-SNE (да, по нему тоже лучше писать отдельную статью):
- большая вычислительная сложность. Вот эта реализация sklearn скорее всего не поможет в Вашей реальной задаче, на больших выборках стоит посмотреть в сторону Multicore-TSNE;
- картинка может сильно поменяться при изменении random seed , это усложняет интерпретацию. Вот хороший тьюториал по t-SNE. Но в целом по таким картинкам не стоит делать далеко идущих выводов – не стоит гадать по кофейной гуще. Иногда что-то бросается в глаза и подтверждается при изучении, но это не часто происходит.
И еще пара картинок. С помощью t-SNE можно действительно получить хорошее представление о данных (как в случае с рукописными цифрами, вот хорошая статья), а можно просто нарисовать елочную игрушку.


Домашнее задание № 2
Актуальные домашние задания объявляются во время очередной сессии курса, следить можно в группе ВК и в репозитории курса.
В качестве закрепления материала предлагаем выполнить это задание – провести визуальный анализ данных о публикациях на Хабрахабре. Проверить себя можно отправив ответы в веб-форме (там же найдете и решение).
Обзор полезных ресурсов
Статья написана в соавторстве с yorko (Юрием Кашницким).
Источник статьи: http://habr.com/ru/company/ods/blog/323210/