- Визуализация данных с использованием matplotlib и seaborn на Python
- Что такое визуализация данных?
- Импорт библиотек для визуализации данных
- Scatter, Точечный график
- Pair plot, Парный график
- Box plot, Ящик с усами, диаграмма размаха
- Violin plot, Скрипичный график
- Joint plot, Гибридный график
- Line plot, Strip plot, Линейный график
- Функция lmplot ( ) в seaborn
- Ящики, усы и скрипки
- Ящики с усами python
- 5 графиков для Data Science, которые можно построить в Pandas 3 способами
- 5 графиков для Data Science, которые можно построить в Pandas 3 способами
- Продолжаем пробовать вино
- Диаграмма рассеяния 1-м методом построения
- Линейный график
- Барный график2-м методом построения
- Гистограмма 3-м методом построения
- Ящик с усами
- Подытожим способы построения диаграмм в Pandas:
Визуализация данных с использованием matplotlib и seaborn на Python
В этой статье мы разберем, что такое визуализация данных и как ее можно использовать для создания графиков с использованием matplotlib и seaborn в Python. Мы также поговорим о различных типах анализа наряду с наиболее распространенными типами графиков, используемых при визуализации данных.
Что такое визуализация данных?
Визуализация данных является формой визуальной коммуникации. Она включает в себя создание и изучение визуального представления данных .
Мы будем реализовывать различные методы визуализации данных в наборе данных ‘iris’.
Различные виды анализа:
- Univariate (U ) : в одномерном анализе мы используем одну особенность для анализа ее свойств.
- Bivariate (B ) : когда мы сравниваем данные между двумя точками, это называется двумерным анализом.
- Multivariate (M ) : Сравнение более 2 переменных называется многомерным анализом.
Наиболее распространенные типы графиков, используемых при визуализации данных:
- Scatter plot, Точечный график (B )
- Pair plot, Парный график (М )
- Box plot, Ящик с усами, диаграмма размаха (U )
- Violin plot, Скрипичный график (U )
- Distribution plot, График распределения (U )
- Joint plot, Гибридный график (U ) & (B )
- Bar chart, Гистограмма (B )
- line plot, Strip plot, Линейный график (B )
Давайте посмотрим на некоторые из этих графиков, используемых при визуализации данных:
Импорт библиотек для визуализации данных
Сначала нам нужно импортировать две важные библиотеки для визуализации данных —
Matplotlib — это библиотека Python, широко используемая для визуализации данных . В то время как Seaborn представляет собой библиотеку Python, основанную на matplotlib. Seaborn предоставляет высокоуровневый интерфейс для проектирования статистических график в привлекательной и информативной формах.
Загрузить файл в dataframe
Scatter, Точечный график
Это один из наиболее часто используемых графиков для простой визуализации данных. Он дает нам представление о том, где присутствуют каждая точка во всем наборе данных относительно любых 2 или 3 объектов (или столбцов). Они доступны как в 2D, так и в 3D.

Pair plot, Парный график
Допустим, у нас есть n объектов в наших данных. Парный график поможет нам создать фигуру (nxn ), где диагональные графики будут гистограммами объектов, соответствующих этой строке, а остальные графики представляют собой комбинацию объектов, — каждая строка по оси y и элемент из каждого столбца по оси x.
Фрагмент кода для парного графика, реализованного в наборе данных Iris:

Box plot, Ящик с усами, диаграмма размаха
Квадратный график (или блочный график) показывает распределение количественных данных таким образом, чтобы облегчить сравнение между переменными или по уровням категориальной переменной . Окно показывает квартили набора данных, а усы расширяются, чтобы показать остальную часть распределения.
Код для построения объектов с использованием Box plots:

Violin plot, Скрипичный график
Графики скрипки могут быть выведены как комбинация ящика с усами и графика распределения с обеих сторон данных . Это может дать нам детали распределения, такие как мультимодальное распределение, асимметрия и т. д.
Скрипичный график тоже из seaborn. Код прост и выглядит следующим образом.

Joint plot, Гибридный график
Гибридный графики могут выполнять как одномерный, так и двумерный анализ . Основной график даст нам двумерный анализ, в то время как на верхней и правой части мы получим одномерные участки обеих переменных, которые были анализированы. Это облегчает нашу работу, получая как диаграммы рассеяния для двумерного, так и график распределения для одномерного, что примечательно оба в одном.
Есть различные опции которые вы можете выбрать и настроить с использованием параметра kind функции jointplot в seaborn:

Line plot, Strip plot, Линейный график
Линейный график может быть использован сам по себе, но он также является хорошим дополнением к ящику с усами или скрипичному графику в тех случаях, когда вы хотите показать весь анализ вместе с некоторым представлением основного распределения.
Это метод анализа графических данных для суммирования одномерного набора данных. Обычно он используется для небольших наборов данных.

Функция lmplot ( ) в seaborn
Lmplot от Seaborn — это двумерная диаграмма рассеяния с дополнительной наложенной линией регрессии. Логистическая регрессия для двоичной классификации также поддерживается с помощью lmplot. Он предназначен в качестве удобного интерфейса для подгонки регрессионных моделей к условным подмножествам набора данных.
Функция может нарисовать диаграмму рассеяния двух переменных, x и y затем подогнать регрессионную модель y
x и построить результирующую линию регрессии с 95% доверительным интервалом для этой регрессии.
lmplot ( ) имеет data в качестве требуемого параметра и x и y переменные должны быть заданы как строки.

Заключение:
Визуализация данных не только помогает вам лучше анализировать ваши данные, но всякий раз, когда вы обнаруживаете какие-либо идеи, вы можете использовать эти методы, чтобы поделиться своими результатами с другими людьми в простой и интуитивно понятной форме.
Источник статьи: http://coincase.ru/blog/47592/
Ящики, усы и скрипки

Очень часто данные необходимо сравнивать. Например, у нас есть несколько рядов данных из какой-то области деятельности человека (промышленности, медицины, государственного управления, …), и мы хотим сравнить, насколько они похожи или, наоборот, чем одни показатели выделяются по сравнению с другими. Для простоты восприятия возьмем данные более простые, универсальные и нейтральные — высоту в холке и вес нескольких пород собак по сведениям Американского клуба собаководства (American Kennel Club). Данные по размерам пород в среднем можно найти здесь. Прибавим к ним функцию random.uniform из Python-библиотеки numpy, переведем дюймы в сантиметры, а фунты в килограммы, и вот мы получаем реалистично выглядящий набор данных по размерам собак нескольких пород, с которым можно работать. В нашем примере это чихуахуа, бигли, ротвейлеры и английские сеттеры.

Одну из аналитик, которую можно применить для сравнения этих 4 числовых рядов – посмотреть на их медиану. Она разбивает ряд данных на две части: половина значений меньше медианы и остальная половина – больше. Медианные значения находим, группируя с помощью библиотеки pandas по столбцу «Порода» и применяя к сгруппированным данным функцию median. Аналогично можно было бы посмотреть и другие статистические показатели: среднее значение (mean) и моду (mode).
Видим, что половина встреченных нами чихуахуа имеет высоту в холке не больше 18 см, бигль значительно выше – в районе 41 см, и следующие по размерам – ротвейлер и английский сеттер, которые отличаются по росту незначительно: 58 и 63 см.

Рисунок 2. Медианные значения высоты в холке четырех пород собак.
Но только одной медианы недостаточно для сравнительного анализа данных. Можно получить больше информации, если рассмотреть такой инструмент как диаграмма размаха (также известная как «ящик с усами», box-and-whiskers plot), построенную с помощью Python-библиотеки для построения графиков seaborn. Линия внутри ящика – это уже знакомая нам медиана. Ее уровень на графике справа (см. Рисунок 3) совпадает с высотой соответствующего столбца слева. Но при этом диаграмма размаха содержит дополнительную информацию о том, как данные распределены внутри ряда: нижняя граница прямоугольника (ящика) – это первый квартиль (величина, превосходящая 25% значений ряда), а верхняя граница – третий квартиль (величина, превосходящая 75% значений). А те самые «усы» — отрезки, отходящие вверх и вниз от середины прямоугольника – строятся на основе интерквартильного размаха и обозначают верхнюю и нижнюю границу значимой части наших данных, исключая выбросы. Здесь выбросы отсутствуют (дистрофиков и собак-гигантов нам в рассмотрение не попадалось), при наличии они отобразились бы метками за пределами «усов».

Рисунок 3. Сравнение столбчатой и диаграммы размаха, построенных для одного и того же набора данных.
Скрипичный график (violinplot) из той же библиотеки seaborn дает нам еще больше информации о структуре рассматриваемых данных. Ниже на Рисунке 4 представлены все три графика, где породы идут каждый раз в одинаковом порядке, а цвет для соответствующего ряда сохраняется.

Рисунок 4. Сравнение столбчатой диаграммы, диаграммы размаха и скрипичного графика, построенных для одного и того же набора данных.
Например, зеленым показаны данные о ротвейлерах.
Сходства и различия диаграммы размаха (ящика с усами) и скрипичного графика показаны на следующем Рисунке 5. Сначала сходства: (1) оба графика в том или ином виде отражают 0.25-квантиль, 0.5-квантиль (медиану) и 0.75-квантиль; (2) и там, и там отражаются крайние значения, которые близки к величине полутора межквартильных интервалов (IQR), отложенных от нижнего и верхнего края коробки – те самые «усы» для диаграммы размаха, за пределами которых находятся «выбросы».
Отличие же состоит в том, что скрипичный график содержит также информацию о том, как данные распределены внутри, т.к. границы построенной «скрипки» — это повернутая на 90 градусов плотность распределения. И в этом случае при анализе графика у нас гораздо больше информации: в дополнение к квантилям и значениям, описывающим 4 интерквартильных расстояния (1.5 + 1 + 1.5) на скрипичном графике можно увидеть, распределены ли данные равномерно или есть несколько центров, где значения встречаются более часто.

Рисунок5. Пояснения по соответствию элементов двух графиков: размаха и скрипичного.
Более ярко эту мысль можно увидеть на следующем графике (Рисунок 6), где данные по двум группам ротвейлеров отличаются, но подобраны таким образом, что медианы совпадают (крайний слева график) и даже больше – диаграммы размаха (в центре) тоже совпадают! И только скрипичный график (крайний справа) показывает нам, что на самом деле структура данных значительно отличается.

Рисунок 6. Пример, когда только скрипичные график позволяет нам увидеть отличия во внутренней структуре рассматриваемых данных.
Используя кластеризацию К-средних (cluster.KMeans) из модуля sklearn, мы можем визуально представить сгруппированные данные, построив диаграмму разброса с помощью функции scatterplot модуля seaborn. Здесь цвет отделяет один кластер, созданный ML-алгоритмом, от другого, а форма маркера показывает исходную принадлежность к той или иной группе. Понижать размерность с помощью PCA или какого-либо другого метода здесь было не нужно, т.к. данные изначально 2D.

Код для кластеризации и построения диаграммы разброса:


Таким образом, на примере данных о высоте в холке нескольких пород собак мы познакомились с некоторыми статистическими характеристиками числовых рядов и инструментах их визуализации. Простой инструмент дает понятную метрику, но не дает полной картины. Более сложные инструменты дают более глубокую картину данных, но и воспринимаются также сложнее в силу увеличения количества информации на графике. И здесь важно выбирать инструмент под конкретную задачу, чтобы находить баланс между требующейся полнотой информации и простотой ее восприятия на графике.
Источник статьи: http://habr.com/ru/post/533726/
Ящики с усами python
5 графиков для Data Science, которые можно построить в Pandas 3 способами
5 графиков для Data Science, которые можно построить в Pandas 3 способами
В прошлой статье мы рассказали о том, как важно визуализировать данные в Data Science и Machine Learning. Также мы научились строить такие графики, как линейный, барный, диаграмму рассеяния, гистограмму и ящик с усами, в Python c библиотекой matplotlib. Сегодня мы покажем вам, как эти же самые графики могут быть построены в pandas без явного импортирования matplotlib, причем 3 разными способами. Предварительно отметим: pandas использует библиотеку matplotlib для визуализации, хотя в коде мы не будем ее импортировать, тем не менее она должна быть установлена. Если у вас ее нет, введите в командной строке:
Продолжаем пробовать вино
В качестве примера возьмем тот же самый датасет Kaggle с отзывами о винных изделиях разных стран, который мы обсуждали ранее:
Первые пять строк датасета выглядят следующим образом:
 Отображение 5 первых строк в Pandas
Отображение 5 первых строк в Pandas
Ключевыми атрибутами являются price – цена и points – балы. А теперь приступим к изучению визуализации данных в pandas.
Диаграмма рассеяния 1-м методом построения
В диаграмме рассеяния каждая точка одного атрибута соответствует каждой точке другого. 1-й метод построения заключается в том, что у DataFrame есть метод plot [1], одним из аргументов которого является kind, определяющий вид графика. И раз у нас точечный график, нужно указать scatter:
Отметим, анализируемые атрибуты указываются как строки, по x и y . Pandas уже сам поймет, что именно строить, к тому же он еще и подпишет соответствующие оси:
 Отобажение диаграммы рассеяния pandas
Отобажение диаграммы рассеяния pandas
Линейный график
Линейный график строит переход от точки к точке. Построим такой график, где для каждого бала будем брать среднюю цену:
Здесь, мы не указывали аргумент kind , так как pandas по умолчанию строит именно линейный график. Результат:
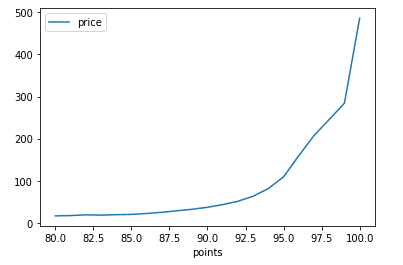 Линейный график
Линейный график
Pandas даже предоставил легенду price на графике, что очень удобно, когда этих линий очень много.
Барный график 2-м методом построения
На барном графике каждая категория в виде бара имеет высоту, соответствующую числовому значению этой категории. Построим первые 7 стран по производству вина:
2 метод построения – вызов конкретного графика через метод plot . Таким образом, барный график будет выглядеть так:
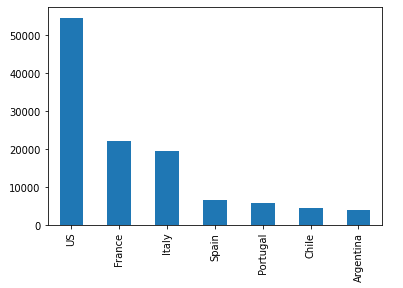 Барный график
Барный график
Подобным же образом можно вывести и другие вида графиков в Python:
Заметим, у такого способа отсутствует возможность вызова boxplot , поэтому для визуализации ящика с усами используется 1-й или 3-й способ.
Гистограмма 3-м методом построения
В машинном обучении плотности распределения служат хорошим инструментом анализа, особенно для линейных моделей. Например, плотность распределения остатков близкое к нормальному показывает, что на этих данных можно построить линейную регрессию. Гистограммы могут помочь с этим.
Здесь указан 3-й способ получения графиков. DataFrame имеет методы hist , bar , scatter и т.д., с которыми можно работать. Только нужно заметить, что метод hist имеет аргументом column , в которую передается необходимый столбец. Не указав его, pandas построит гистограммы для всех числовых атрибутов. Данная гистограмма выглядит вот так:
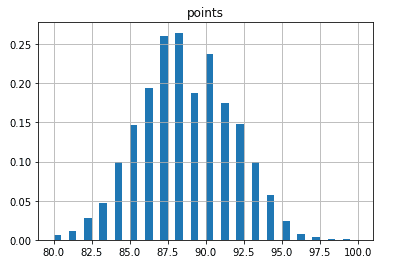 Отображение гистограммы pandas
Отображение гистограммы pandas
Ящик с усами
В прошлый раз мы строили ящик с усами, показывающий размах данных, на всем наборе баллов датасета. Проделаем аналогичное через метод boxplot (3-й метод):
Вид графика c теми же двумя выбросами представлен следующим образом:
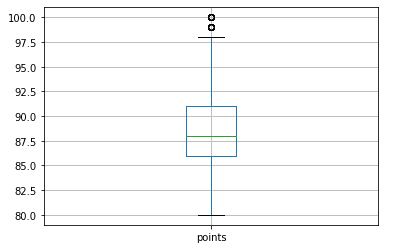 Ящик с усами
Ящик с усами
Такая запись очень короткая, что очень в стиле Python. Лаконичный код позволяет не отвлекаться от основных дел – создания модели Machine Learning, например. Но стоит заметить, у DataFrame нет метода scatter , поэтому для диаграммы рассеяния придется использовать только 1-й способ.
Подытожим способы построения диаграмм в Pandas:
- Метод plot у DataFrame, принимающий в качестве аргумента kind , который определяет вид графика. Например,
построит барный график. Этим способом можно построить все вышеперечисленные графики.
Все примеры находятся в репозитории на github [2]. В следующей статье мы научимся работать с тензорами в numpy.
Визуализация данных без ее интерпретации может нести мало информации. В нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве мы поможем вам не только строить графики в Python, но и читать их.
Источник статьи: http://python-school.ru/data-vizualization-basic-pandas/